Erlang Process Monitoring
If you’ve heard much about Erlang you probably encountered a mass of giddy enthusiasts sounding almost sensationalist when they describe how Erlang is immensely fault-tolerant, with a billion 9s of reliability. Ok, they’re actually a different breed to the Ruby folk, but they do puff their chests a little bit about how Erlang handles fault-tolerance.
It’s a feature I’ve recently read about — thus warranting a contrived example for my own learning. It’s 2am and I can’t sleep, so I may as well blog about it.
By the way, you work as a developer for a price-aggregating startup. Your job is to make a highly-available aggregator. Unfortunately one supplier doesn’t have an API, so you best get scraping. Here’s an exampleNo Concurrency
Before we start trapping exits and spawning processes across a cluster of nodes, let’s see what the conventional synchronous model can do for us…. which is handy, because the CTO has provisioned only one box for the live system.
https://gist.github.com/3393952.js?file=scraper.erl
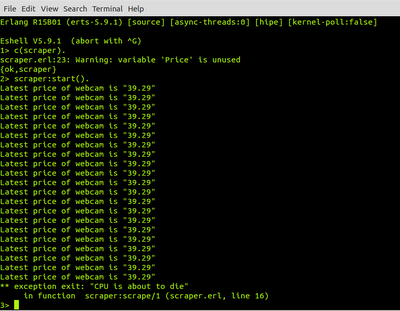
As promised, this example is contrived and ecologically-invalid. We start the scraper, which sets of the recursive scrape function. Each time it recurses it increments the X counter by 1, so that after 20 iterations we emulate a failure condition by calling exit() which kills the process.
Let’s compile the module and check out the output…
If you think about it, error-handling is pretty futile when our hardware is melting.
Or is it? What if the error handling lived on a different box?Multicore Model
Our startup hasn’t really taken off. You did a good job of parsing html using only regex, but the system is unreliable. So unreliable that mr CTO finally splashed out on a few new production boxes to sit around redundant until there is a failure.
Here’s what you designed and pitched to the management team to improve the availability issues:
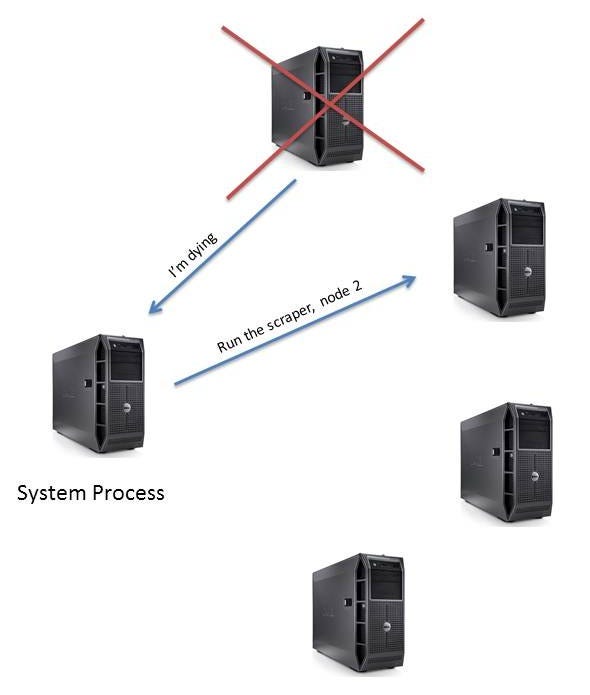
You have one box exclusively for monitoring (home of the system process) the other processes . When one of them develops a fault, the system process will get the message and start a new process on another box in our Erlang cluster.
Here is the beautiful Erlang you createad:
https://gist.github.com/3393954.js?file=mcsraper.erl
First of all, we start a process (spawn()) that begins with start_scraper_with_monitoring(). This process then says: “I am going to handle errors for processes I am linked to”, with the call to process_flag(trap_exit, true) — making it a system process. The next line then links the system process to the newly-created process the scraper has been started on. We need to use our imagination here and pretend this has been started on another network node.
Below that is where the system process listens for messages that are sent to it. Specifically it is only looking for exit messages thrown by a linked process. One of these is sent when the scraper process calls exit().
When we do get an exit, this scraper the function recurses causing the scraper to be started on another node, with that node again being linked to the same monitoring process.Internet Sensation
Just as the capital was about to run-dry, this creeking startup pulls it out the bag. Consumers are loving it, and the bosses are actually managing to smile thrice a week. All this because the system is actually online all the time.
Let’s see how this all came about:
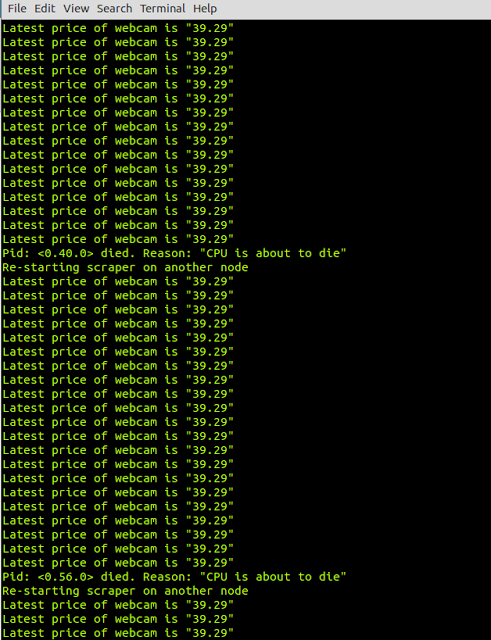
Every time the CPU died and the machine went down, the system process spawned a new process for the scraper to run in, on a node that was available (pretend it did anyway).Hang on a Minute
I hope you didn’t get the impression I know what I’m talking about. I know little about Erlang, and have written somewhere in the region of 0 lines of production Erlang code. Nevertheless, I’ve demonstrated how one process can monitor another and act upon failure of the other node, which can definitely apply to more ecologically-valid use-cases.
All the code lives here: https://github.com/NTCoding/Erlang_Playground/tree/master/PriceScraperFaultMonitoring