Extracting your software architecture with ts-morph
Humans and AI work better when we understand more about the complex systems we're dealing with

I’ve always been interested in improving the understandability of software systems. So much complexity is hidden in the code and the only way to understand is to work in the codebase for a long time or ask people for sketches and diagrams (I don’t need to explain why that’s not ideal).
In my last post I shared a proof of concept I’ve worked on, highlighting the potential for both humans and AI if we can map out the behaviour of our systems.
But the limitation of that approach is relying on LLMs to reverse engineer a codebase — they’re non-deterministic and they hallucinate. For many use cases, that’s too much of a risk.
That’s where tools like ts-morph start to become very interesting…
This is one post in a series. You can find the other posts here: https://medium.com/nick-tune-tech-strategy-blog/software-architecture-as-living-documentation-series-index-post-9f5ff1d3dc07
This post is 100% human-created content. All mistakes are mine
Modelling your architecture
Tools like ts-morph provide the ability to navigate ASTs. We can use them to extract concepts from our code — based on conventions we use to build our systems — and turn that into a model, deterministically. Humans and agents can then benefit from that.
I began my latest experiment from the ground up: let’s first try to extract individual business transactions from a codebase. Then the next step can be to think about chaining transactions in a single codebase then across multiple codebases (I started to explore that in the next post).
The end result looks like this. For every API endpoint or event handler, I can see the domain operations, state changes, and events produced. This is the living documentation I want from a DDD perspective.
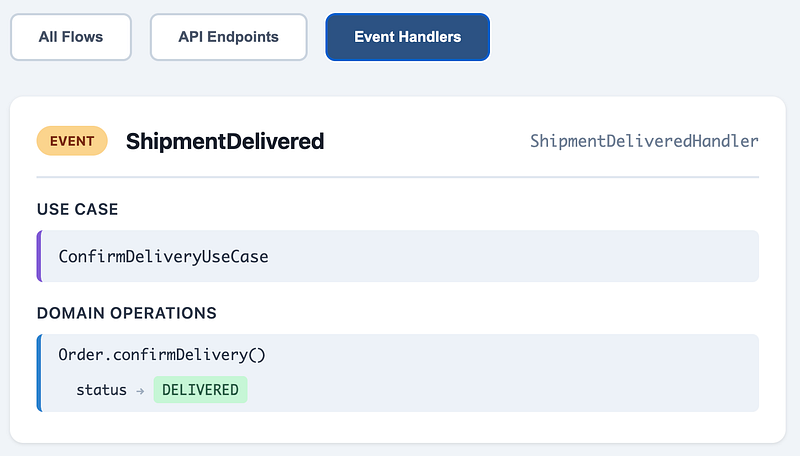

Conventions
Tools like ts-morph will apply to rules to extract concepts from your code. For example, the above image is enabled by a convention that identifies API identifies like this:
findApiEndpoints(): ApiEndpoint[] {
const endpoints: ApiEndpoint[] = [];
const controllerFiles = this.project.getSourceFiles('**/controllers/**/*-controller.ts');
for (const sourceFile of controllerFiles) {
const classes = sourceFile.getClasses();
for (const classDecl of classes) {
if (classDecl.getName()?.endsWith('Controller')) {
...
}
}
...
}
}Basically, controllers live in a certain folder and have the ‘Controller’ suffix in their name. The URL path comes from a parameter called _path on the method.
That will identify code elements like:
export class OrderController {
...
postStartOrder(_path: '/orders/start', command: StartOrderCommand): Order {
const order = this.startOrderUseCase.apply(command);
this.orders.set(order.getId(), order);
return order;
}
postPlaceOrder(_path: '/orders/:id/place', command: PlaceOrderCommand): Order {
const order = this.orders.get(command.orderId);
if (!order) {
throw new Error(`Order ${command.orderId} not found`);
}
return this.placeOrderUseCase.apply(command);
}
...
}For extracting state changes, this example looks for classes that extend Aggregate and operations inside those methods that modify a state variable.
if (baseClass && baseClass.getName() === 'Aggregate') {
const stateChanges = this.extractStateChanges(decl, methodName);
operations.push({
aggregateClass: decl.getName() || 'Unknown',
method: methodName,
stateChanges,
});
}That will match:
export class Order extends Aggregate {
...
place(): void {
if (this.status !== 'STARTED') {
throw new Error(`Cannot place order in ${this.status} status`);
}
this.status = 'PLACED';
this.addDomainEvent(new OrderPlaced(this.id, this.customerId, this.items));
}
...
}Overall: pretty basic reflection stuff to identify some components, but more complicated depending on how you model your domain and how well your codebase follows conventions. Much harder in legacy systems.
I think the key is defining building blocks in a codebase and defining architectural rules to ensure those conventions are applied. Then the output of ts-morph is guaranteed to be accurrate.
Meta Model
The conventions are effectively a utility for extracting the elements of a meta model. In my meta model, the concepts and relationships that are important to me are the flows of entry points, domain operations, events produced, and state changes.
I use ts-morph to extract these concepts and then map them onto my model.
export interface EntryPoint {
type: 'api' | 'event';
name: string;
location: string;
}
export interface StateChange {
property: string;
newValue: string;
}
export interface DomainOperation {
aggregateClass: string;
method: string;
stateChanges: StateChange[];
}
export interface Flow {
entryPoint: EntryPoint;
useCase: string;
domainOperations: DomainOperation[];
eventsProduced: string[];
}The unspectacular output then looks like this:
"flows": [
{
"entryPoint": {
"type": "api",
"name": "POST /orders/start",
"location": "OrderController.postStartOrder"
},
"useCase": "StartOrderUseCase",
"domainOperations": [
{
"aggregateClass": "Order",
"method": "start",
"stateChanges": [
{
"property": "status",
"newValue": "STARTED"
}
]
}
],
"eventsProduced": [
"OrderStarted"
]
},There are other important concepts I want like external service calls and value objects.
Having a model is great because I can generate multiple different views with different levels of detail based on the same model.
Let’s make understandability a basic requirement
Coding agents can help us in various ways like solving bugs faster. But they are limited by how well they understand our systems. Often, they will produce utter nonsense because they don’t understand the whole complex system well enough.
By modelling the concepts in our software, we can empower agents to be more helpful by avoiding their biggest limitations.
To be honest, we shouldn’t need the excuse of AI. Understanding systems is important for humans. Reading and understanding code and systems is what we probably do the most.
The means to do this have always been within reach. AI just means we now have two very compelling reasons to invest in understandability.