Enterprise-wide Software Architecture as DDD Living Documentation
Can the architecture of our company's entire software architecture be a living documenation?

In this series of posts I’m trying to understand the value of extracting ddd-type architectural information from codebases as living documentation. How useful is it to AI and how useful is to humans?
In the first post I concluded that it is very useful to both groups (my conclusion was also based on real work examples as well). Seeing end-to-end flows is something that reduces guesswork and misassumptions and allows us to see the bigger picture (and interact with it).
But asking coding agents to reverse engineer a system has limitations. So in the last post I shared a basic proof-of-concept using ts-morph to extract ddd-type architectural information from a codebase — entry points, domain operations, events, event handlers and so on.
I feel this approach can definitely work, it will just take more or less effort depending on the conventions in a codebase.
So the next question is, how to make this work at a whole-system level?
This is one post in a series. You can find the other posts here: https://medium.com/nick-tune-tech-strategy-blog/software-architecture-as-living-documentation-series-index-post-9f5ff1d3dc07
One model, many views
One of the principles behind Structurizr is one model of the system that can be used to produce many views. In my original POC, Claude Code scanned the codebase and directly created the mermaid. But mermaid is more the visualization language than the underlying model.
If we apply the OMMV principle to our whole-system DDD living documentation challenge, we can use an aggregation component that aggregates output of each domain to create the underlying model, a graph of the system and it’s dependencies.
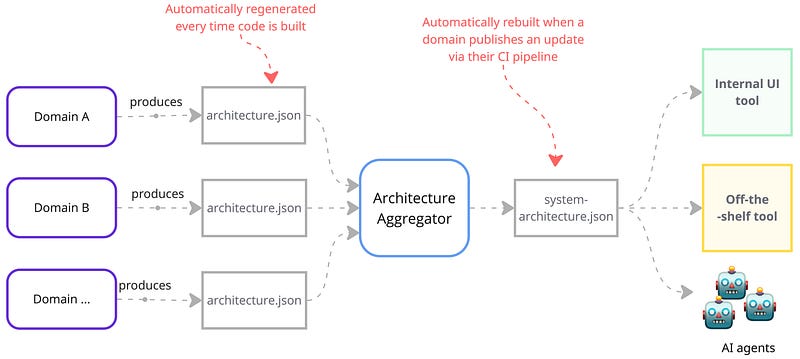
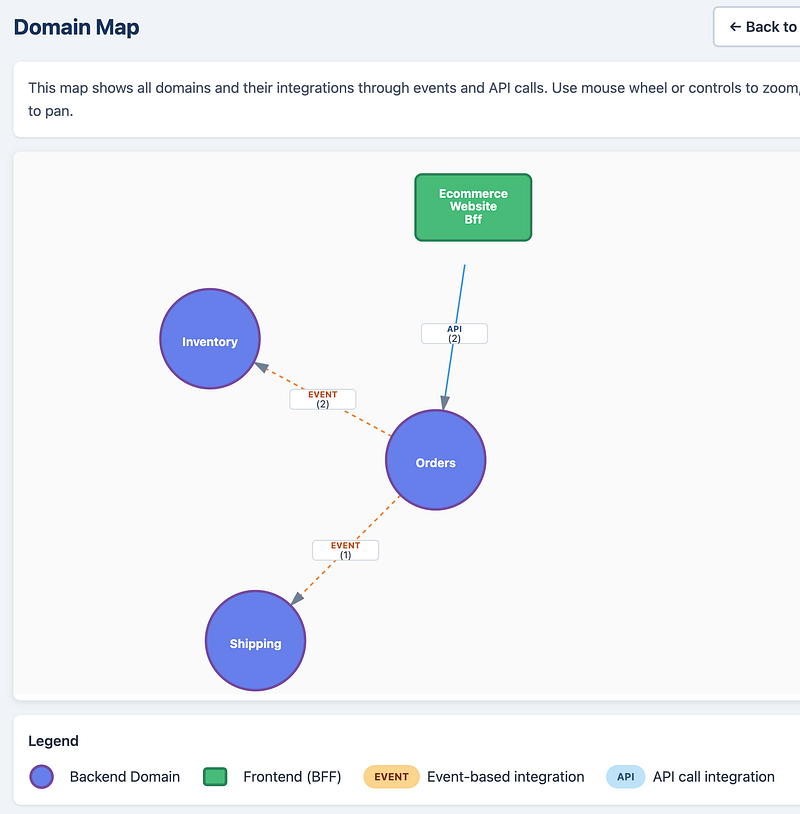
Then we can generate different types of visualization and different levels of detail — all based on data extracted directly from the code. For example, a high-level map showing the integrations that happen between the different domains.
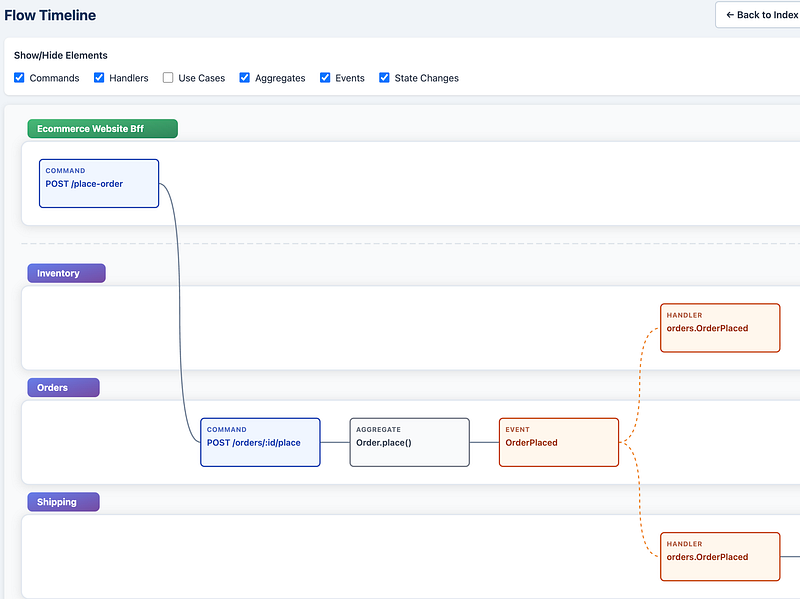
Or an EventStorming/UML Activity — style diagram that shows interactions across different parts of the system with each as a separate swimlane.
Additionally, it’s easy to create a strong link between the implementation and the diagram by linking to the code or showing actual parts of the code in the diagram.
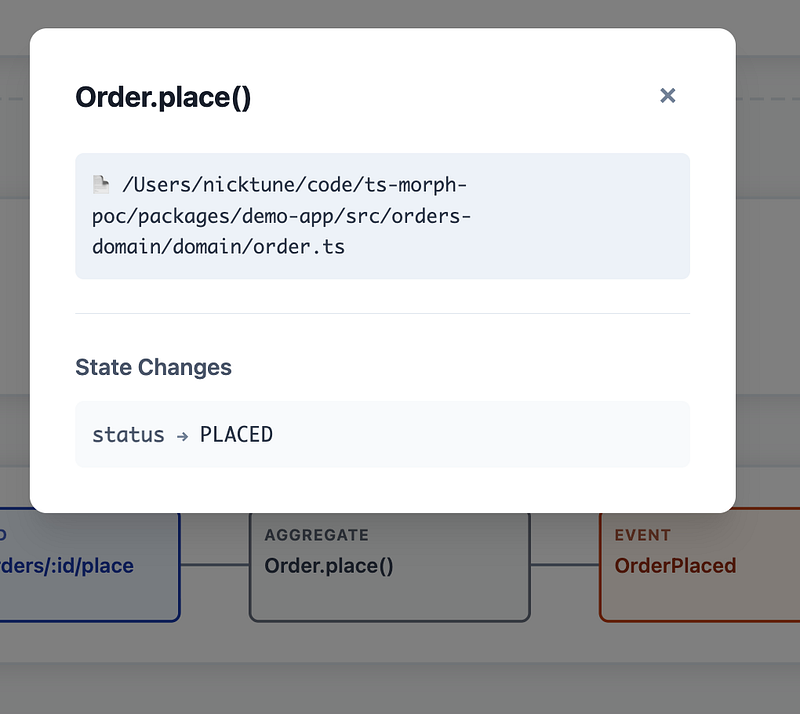
The visualizations above are living documentation generated directly from the code of a sample application. They’re not just mock ups. I’ve tested the concept end-to-end, but it is only a small sample application.
Where are the challenges?
I think the challenges for building this type of system are more conceptual and organizational than technical in nature. If you can agree on the schema of the architecture.json files (or whatever system you use) and each domain produces that information consistently, the job of the aggregator shouldn’t be too difficult. It just needs to accurately identify the dependencies from one system to another.
Some things are pretty standard: API endpoints, events published, database operations, http calls. If you only extract this it’s still incredibly useful showing dependencies.
But when we get more into the domain model — not every codebase will follow the same patterns. So finding a generic term that accurately describes each variation will be challenging (hey, that sounds like DDD). For example, I use the terms domain operation and state change in the model, which could be modelled via OO or functional programming, doing DDD or not doing DDD.
export interface Flow {
entryPoint: EntryPoint;
useCase: UseCase;
domainOperations: DomainOperation[];
eventsProduced: string[];
apiCalls?: ApiCall[];
}
export interface DomainFlows {
domain: string;
analyzedAt: string;
totalFlows: number;
events: Array<{ name: string; filePath: string }>;
flows: Flow[];
isFrontend: boolean;
}
export interface FlowRelationship {
type: 'api-call' | 'event-based';
sourceFlowId: string;
targetFlowId: string;
eventName?: string;
operationId?: string;
}At PayFit we have some guidelines around preferred naming conventions. We prefer the term use case for the DDD application layer which sometimes people refer to as application services.
I think this is where architects working with platform engineers might be most effective for current challenges — defining their organization’s model of architecture and working with teams to provide them the tools to reliably extract the information from their codebases (coding agents can help with this — analyzing codebase to identify patterns which are defined as rules).
Then there is the question of build-vs-buy. Should you build something internally based around your conventions or use and extend a tool like Structurizr that comes with a community of knowledge and tooling? I’m looking forward to exploring this further…
Next steps…
There’s a lot more I want to dig into across the various elements of this living documentation system:
- Leveraging coding agents to identify and define rules in any codebase
- Architecture models like Structurizr
- Modelling more complex flows with branching
- End-to-end user journeys where there isn’t a hard link in the code
- Reverse-engineering legacy codebases
If you have any knowledge in these topics or are working on similar things I would be grateful for any learning opportunities or just to hear your cool stories.