Event-sourced Claude Code workflows
Storing the state of the workflow as events to enable rich observability and detailed workflow insights and optimizations.
In the previous couple of posts I shared an approach I’ve started using, to design Claude Code workflows as state machines in real code using domain-driven design concepts. And then how to make them more declarative with DSLs.
It was suggested by Yves Reynhout to make the workflows fully event-sourced, by not storing the current state and only storing the events. Then deriving the current state from the events.
So I gave it a try. The implementation was a pretty boring event-sourcing implementation using SQLite for storage. However, the possibilities unlocked are quite exciting - in-depth observability of how my agents performed and where they spent their time implementing a feature, and the potential for cross-session trends analysis.
So far this is just something I’ve tried out on personal projects. However, I think I’ll be using this for real in the near future.
The code for this is in the autonomous-claude-agent-team repo on GitHub.
Observability & suggestions
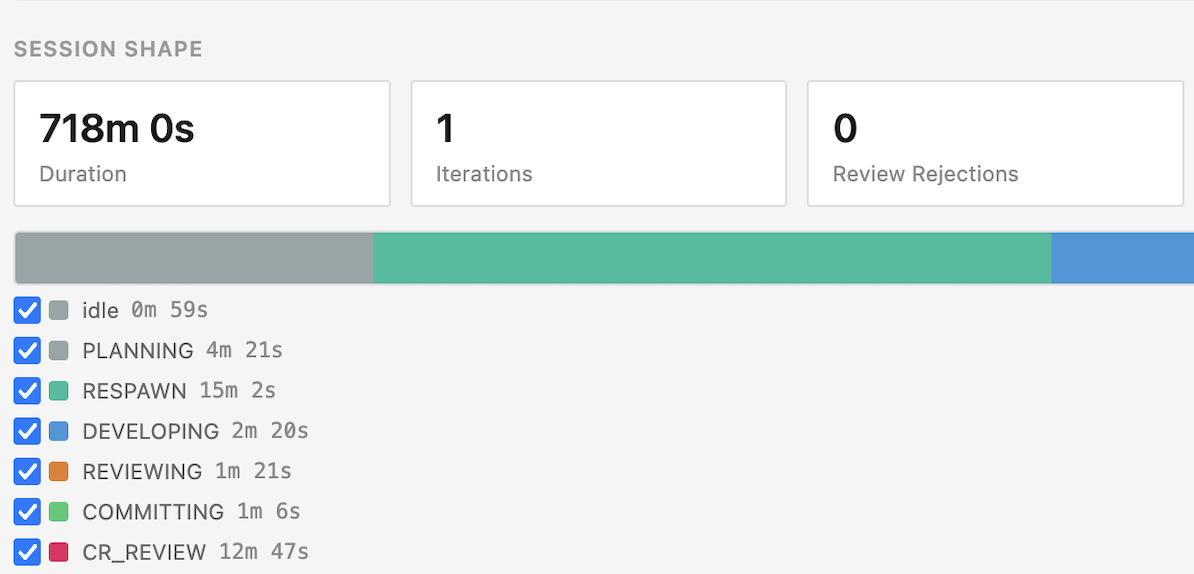
Here is a UI that is generated at the end of a Claude Code session using all of the events persisted by the Workflow state machine. It is built by running /autonomous-claude-agent-team:view-report <sessionId>
Straight away, there are two things here that I think demonstrate the potential:
- What actually happened?
- How can I optimize my workflow / harness / context so that my agents perform better next time?
 Here, I can immediately see that my agents spent 15 minutes in the
Here, I can immediately see that my agents spent 15 minutes in the RESPAWN state whereas they only spent 2 minutes actually building the feature.
What actually happened?
The timeline can easily be calculated using state transition events. When the workflow transitions from DEVELOPING to REVIEWING or COMMITTING to RESPAWNING we can deduce how long was spent in each state.
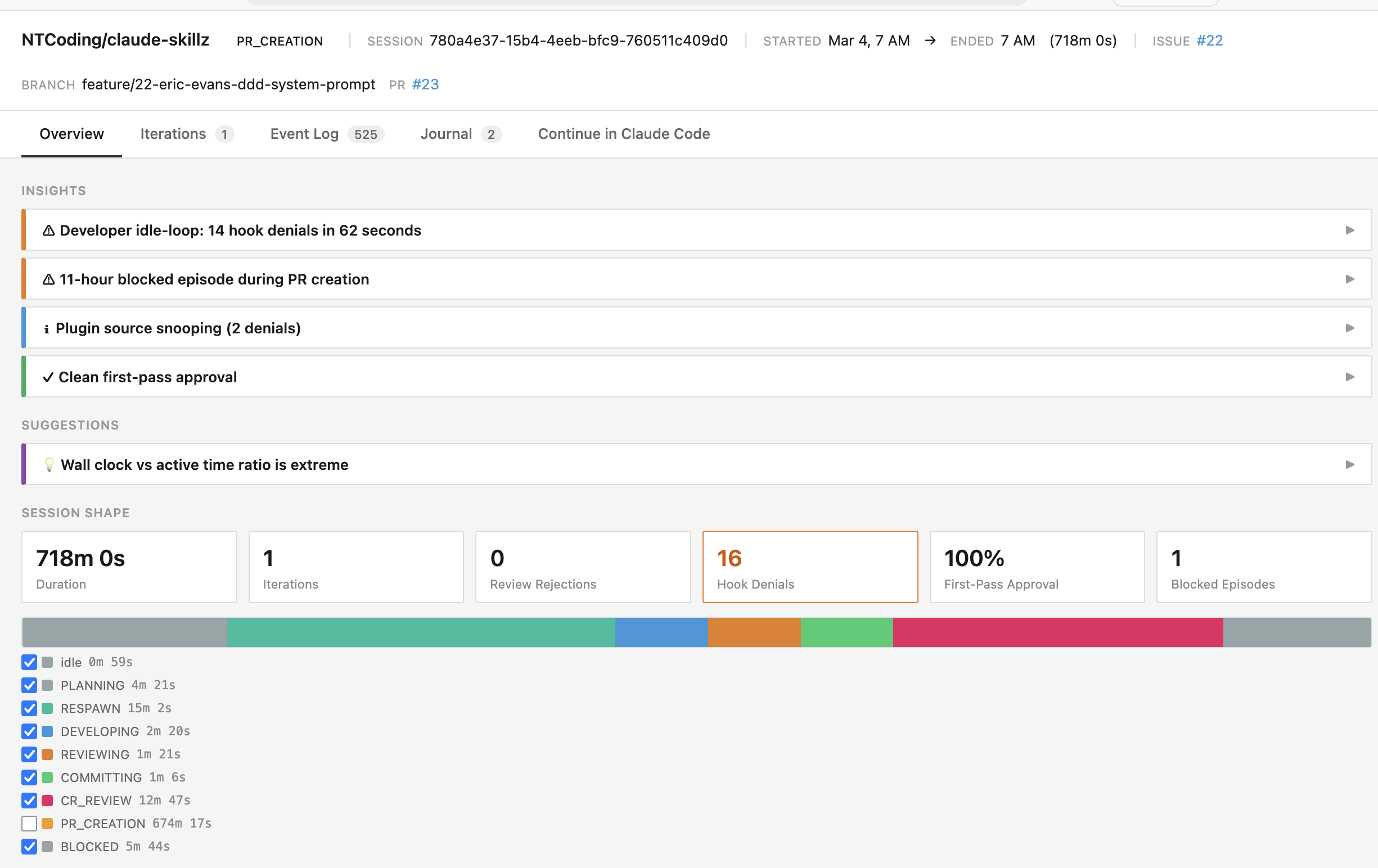
As mentioned above, my agents spent more time in the RESPAWNING state than they did DEVELOPING. That seems problematic, maybe we should optimize that by spawning all of our team members for every iteration up front for example.
Other useful insights are the number of rejections (code review failed) and hook denials (Claude tried to do things that aren’t allowed in that state). Our goal is for these to always be 0, because they indicate a waste of time, waste of tokens, and indicate our agent has sub-optimal instructions.
How can I optimize my harness?
Don’t just build metrics from your events, feed them to your AI assistant. I’ve seen great results on real projects by feeding events into Claude Code and asking it to identify anomalies or improvement opportunities.
What’s really powerful in this scenario is that Claude is able to take the events and also able to combine the event analysis with code, prompts, and any other context that explain the trends. It can identify why problems exist and suggest how to optimize the context or workflow. It might suggest a CLAUDE.md improvement or a tweak to a the system prompt of your code review agent.
Other useful observability features
I decided to use the Workflow’s event stream as the journal. Whenever an agent makes a decision or reaches a key milestone it logs a journal entry. This can be useful for post-hoc analysis and equally when spawning new team members to bring them up to speed.
To make this reliable, my workflow has hard-blocks to ensure the journal entries are written, at-least one per iteration.
Another trivial feature is an event log search. Free text search, type-based search, facets, all of that is pretty trivial and allows you to dig into the details when the high-level stats and insights aren’t enough.
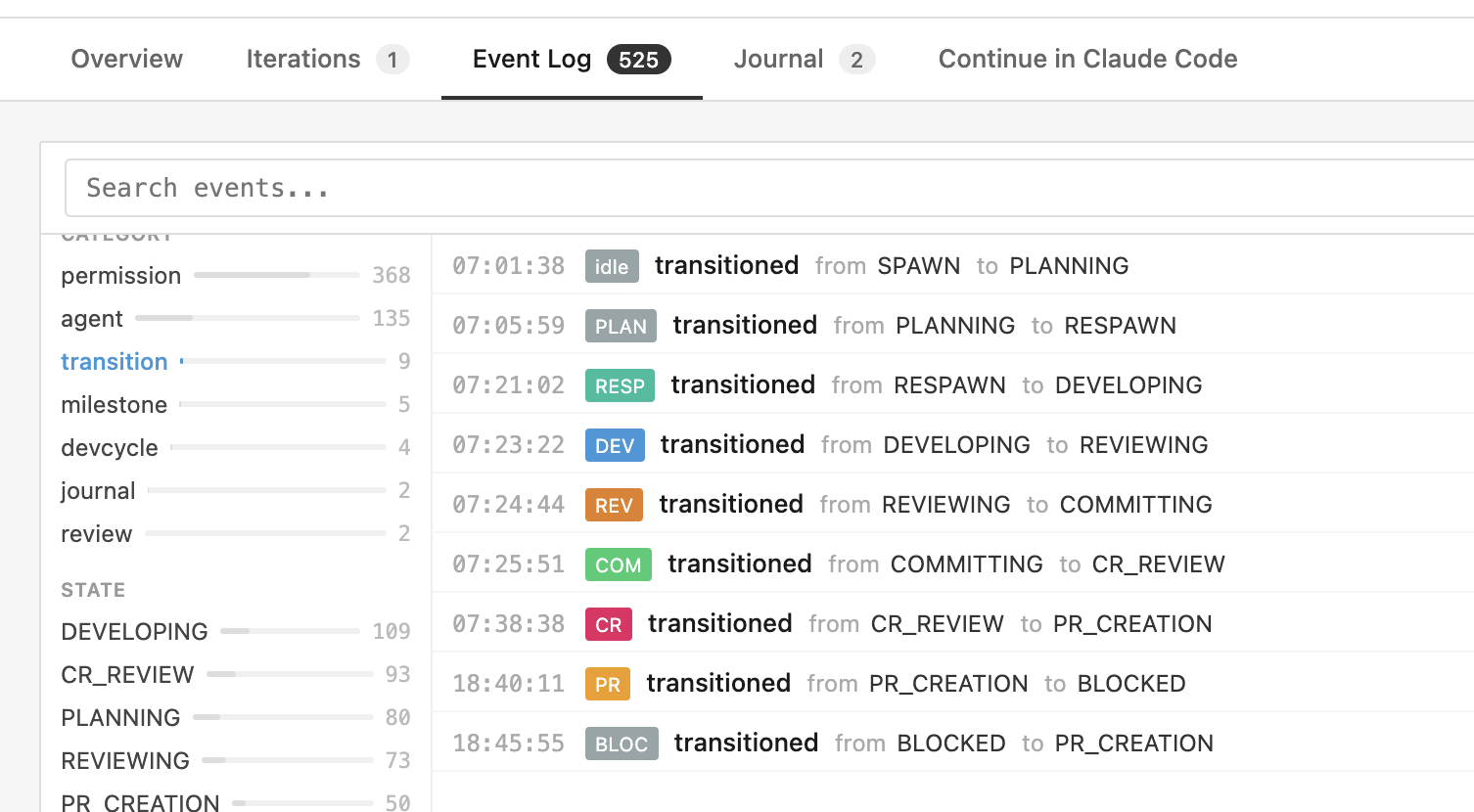
The UI also provides prompts to share with Claude so you can discuss some aspect of the analysis in more detail.
Other possibilities
Something I have not even started to flirt with yet is cross-session analysis. But when you have thousands of events from tens or hundreds of Claude Code sessions, it would be a shame not to try and make use of that: why do certain types of feature take longer? what is common across sessions where code review fails repeatedly?
It would be trivial to also add a real time control center giving you an overview of all your in-progress Claude sessions. It would be able to alert you when an anomaly is detected or you could jump into the details ad-hoc.
Architecture
The architecture is basically the same as before. Except the state-based persistence is replaced with event-based persistence in a SQLite DB.
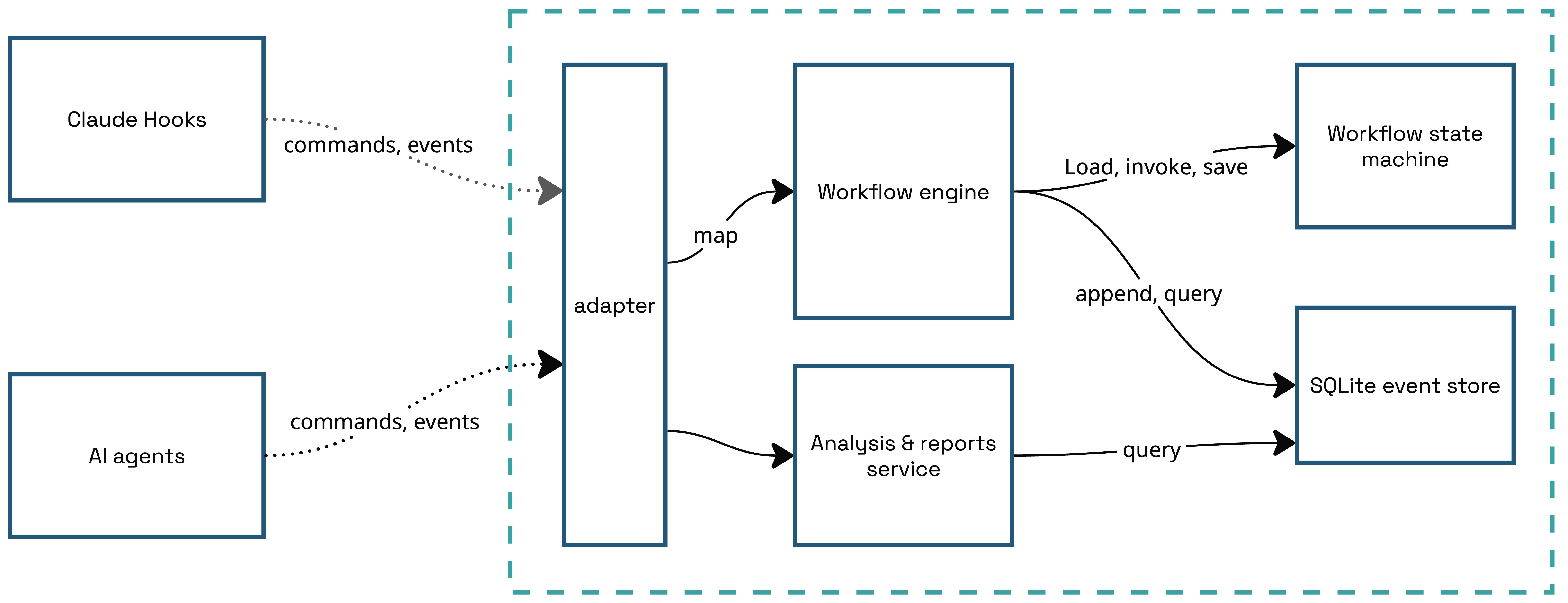
All operations that flow through the Workflow are stored as events and replayed each time to build the state. This could become a performance problem so there are various optimisation opportunities: snapshots, multiple streams, storing some events in an audit log if they aren’t required to build the state (e.g. journal entries), projections, or an MCP server that keeps projections in memory so the state doesn’t need to be rebuilt on every request.
At the end of the day, they are events like those produced by any other software application, so all the same principles and patterns apply. You can use them for analytics, pump them into your observability platform. I imagine a lot of companies are doing this already and I expect more tooling to appear in this space.
Is this really useful?
I don’t think event-sourced aggregates are going to offer much value to the developer that uses Claude Code as a chatbot, or the developer that hand-holds Claude through every session. I believe that this approach could be more suited to developers implementing an autonomous coding loop, where agents build features on their own and there is less human in the loop. That’s what I’ll be using it for.
An open question is whether we can reach a point where our workflows just work. Agents consistently produce good results in an efficient manner. If we get to that point, the observability and analysis doesn’t provide any value.
However, if the future is going to be continuous optimisation of our agentic workflows, then this type of architecture seems inevitable and will be quickly industrialized.