Claude Code workflows as DSL-driven domain models
Evolving the hook-driven workflow engine into a proper domain model, each state declaratively defined in a single DSL-driven file.
In the previous post I showed a hook-driven workflow engine that coordinates Claude Code agent teams from GitHub issue through to PR. Defining workflows as code improves determinism and allows us to unit test the workflows so we can put strong guardrails around Claude and ensure they are working.
Check out the git repo for this post if you want to see the full example.
The original version I created was fully implemented in code. The code had some basic design, separation of concerns and layering, but I was curious if I could make it even easier to see what each step of the workflow does without looking at lots of other code. I wanted something more declarative yet still type safe.
So I started working on a redesign to decouple the declarative workflow steps from the underlying execution mechanics to get the best of both worlds.
Declarative workflow state definitions
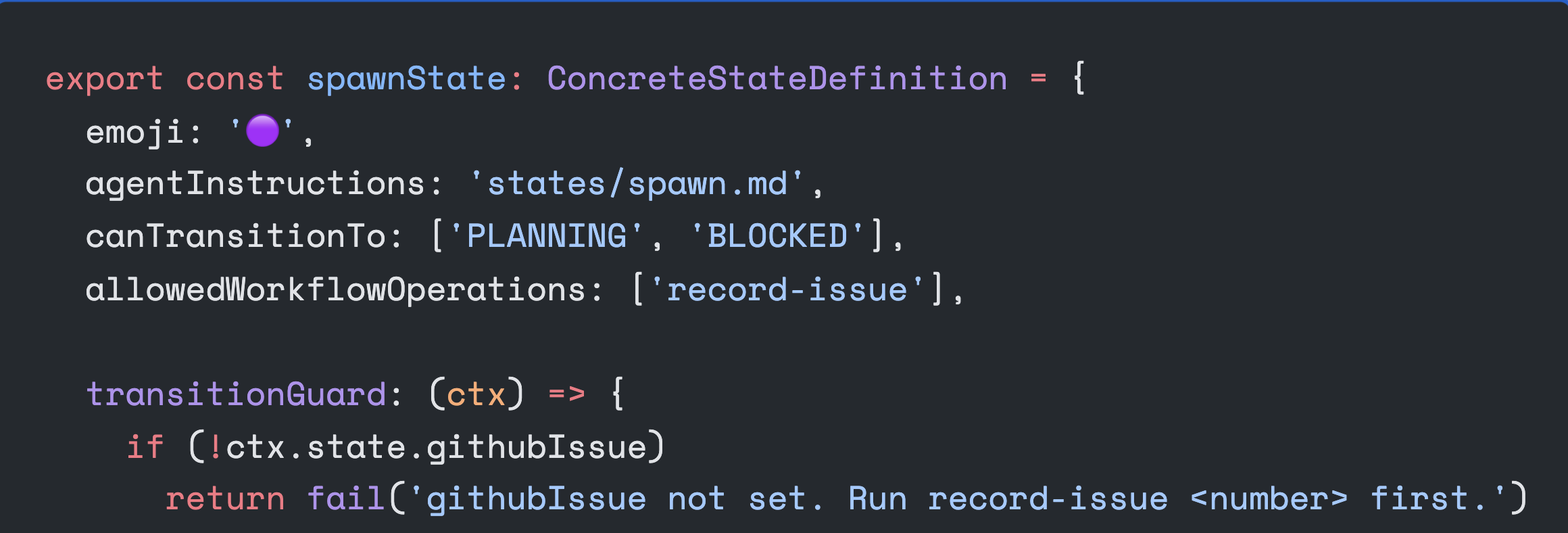
I created a basic DSL that allows me to define workflow states like this:
export const spawnState: ConcreteStateDefinition = {
emoji: '🟣',
agentInstructions: 'states/spawn.md',
canTransitionTo: ['PLANNING', 'BLOCKED'],
allowedWorkflowOperations: ['record-issue'],
transitionGuard: (ctx) => {
if (!ctx.state.githubIssue)
return fail('githubIssue not set. Run record-issue <number> first.')
if (!ctx.state.activeAgents.some((n) => n.startsWith('developer-')))
return fail('No developer agent spawned.')
if (!ctx.state.activeAgents.some((n) => n.startsWith('reviewer-')))
return fail('No reviewer agent spawned.')
return pass()
},
}emoji: the emoji that gets prefixed onto every message during this stateagentInstructions: the prompt that gets injected into the team lead agent when transitioning to this state (these instructions are re-injected if the agent makes a mistake or forgets the workflow)canTransitionTo: the other workflow states that can be transitioned to from this stateallowedWorkflowOperations: the commands on theworkflowaggregate that can be invoked during this statetransitionGuard: a function that takes the current state of the aggregate and decides if it can transition to a new state
The purpose of this is not just elegance or perfectionism. It is productivity: whenever agents are not behaving as I want them to, I go to the relevant state file and add new logic in that state.
Equally, if someone wants to see the workflow, they can quickly learn how it works by looking at the state definitions without having to go through all of the workflow execution logic.
In the original implementation, information about each state is spread across 4 or 5 different files that contain a mix of workflow-specific and generic workflow logic.
The new architecture
ConcreteStateDefinition is a type alias that binds the generic DSL type (WorkflowStateDefinition) to this specific workflow’s state, operation, and command types. The DSL itself is a new module. The new architecture is composed of 3 modules:
workflow-engine: The thing that actually runs and executes the workflow. It doesn’t contain any workflow rules, but it knows how to execute workflow rules and steps that it is given.workflow-dsl: a language for defining workflow steps that theworkflow-enginecan executeworkflow-defintion: the actual workflow itself containingworkflow.tswhich is the aggregate root
There is also entrypoint.ts which is an adapter for Claude Code. It translates Claude Code hooks into operations on the workflow aggregate.

At runtime, Claude Code hooks and agent CLI commands flow through the adapter into the engine:

The same design principles
In addition to the new principle of declarative step definitions, I also wanted to maintain key advantages of the current approach: type safety, compile time validation, full test coverage. That’s why I chose TypeScript over something like YAML.
type safety and compile time safety
The DSL types ensure that state names, operations, and forbidden commands are all union types — not arbitrary strings:
export const STATE_NAMES = [
'SPAWN', 'PLANNING', 'RESPAWN', 'DEVELOPING', 'REVIEWING',
'COMMITTING', 'CR_REVIEW', 'PR_CREATION', 'FEEDBACK', 'BLOCKED', 'COMPLETE',
] as const
export type StateName = (typeof STATE_NAMES)[number]
export type WorkflowOperation =
| 'record-issue'
| 'record-branch'
| 'record-plan-approval'
| 'assign-iteration-task'
| 'signal-done'
// ...The as const array pulls double duty: it feeds both the StateName type (compile-time) and a Zod schema for runtime validation at the adapter boundary:
export const StateNameSchema = z.enum(STATE_NAMES)So when you write canTransitionTo: ['FEEDBACK'] or allowedWorkflowOperations: ['record-pr', 'create-pr'], these are validated at compile time. If you put canTransitionTo: ['ABC'] it won’t compile because ABC is not a member of the StateName union.
domain-driven
This new approach applies domain-driven design even further by making the workflow an explicit aggregate root that everything must pass through. It is the interface that encapsulates all rules, invariants, state transitions, and internal state.
Internally, the Workflow aggregate delegates to logic in the DSL-defined state definitions where necessary. This does add some extra complexity in the sense that logic is split across the aggregate itself and the state files, and there is some generic behaviour in the Workflow. But it’s worth it.
private checkOperationGate(op: WorkflowOperation): PreconditionResult {
const currentDef = getStateDefinition(this.state.state)
if (currentDef.allowedWorkflowOperations.includes(op)) {
return pass()
}
return fail(`${op} is not allowed in state ${this.state.state}.`)
}The entrypoint that is invoked by Claude Code hooks is just an adapter that converts the hook into a command and calls it on the aggregate. It decouples the workflow from Claude:
// Hook handler — parses stdin JSON, calls engine
function handlePreToolUse(engine: WorkflowEngine<Workflow>, deps: AdapterDeps): OperationResult {
const hookInput = parsePreToolUseInput(deps.readStdin())
if (!engine.hasSession(hookInput.session_id))
return { output: '', exitCode: EXIT_ALLOW }
// Engine loads worfklow (w) and persists it after lambda completes
const hookCheck = engine.transaction(hookInput.session_id, 'hook-check', (w) => {
const pluginCheck = w.checkPluginSourceRead(hookInput.tool_name, filePath, command)
if (!pluginCheck.pass) return pluginCheck
const writeCheck = w.checkWriteAllowed(hookInput.tool_name, filePath)
if (!writeCheck.pass) return writeCheck
return w.checkBashAllowed(hookInput.tool_name, command)
})
if (hookCheck.type === 'blocked')
return { output: formatDenyDecision(hookCheck.output), exitCode: EXIT_BLOCK }
// ...
return { output: '', exitCode: EXIT_ALLOW }
}
// CLI command handler — parses args, calls engine
function handleTransition(args: readonly string[], engine: WorkflowEngine<Workflow>, deps: AdapterDeps): OperationResult {
const rawState = args[1]
if (!rawState)
return { output: 'transition: missing required argument <STATE>', exitCode: EXIT_ERROR }
const parseResult = StateNameSchema.safeParse(rawState)
if (!parseResult.success)
return { output: `transition: invalid state '${rawState}'`, exitCode: EXIT_ERROR }
return mapResult(engine.transition(deps.getSessionId(), parseResult.data))
}The adapter does arg parsing, stdin parsing, hook-to-domain translation, and exit code mapping. Zero orchestration logic. The engine handles the session context. Checks if there is a current session, loads the workflow for the current session, persists state if there was an update.
observable by-default
When agents start misbehaving and going off the rails, I need to easily be able to understand why the workflow didn’t prevent it. Therefore, I put an even greater focus on observability. Every operation on the workflow gets logged to its internal event log:
// Every workflow operation appends to the event log
recordIssue(issueNumber: number): PreconditionResult {
// ... validation ...
this.state = {
...this.state,
githubIssue: issueNumber,
eventLog: [...this.state.eventLog,
createEventEntry('record-issue', this.deps.now(), { issueNumber })],
}
return pass()
}The event log is persisted as part of the workflow state. You can inspect it at any time:
{"op": "init", "at": "2026-03-01T10:00:00.000Z"}
{"op": "record-issue", "at": "2026-03-01T10:00:05.000Z", "detail": {"issueNumber": 42}}
{"op": "subagent-start", "at": "2026-03-01T10:00:10.000Z", "detail": {"agent": "developer-1"}}
{"op": "subagent-start", "at": "2026-03-01T10:00:12.000Z", "detail": {"agent": "reviewer-1"}}
{"op": "transition", "at": "2026-03-01T10:00:15.000Z", "detail": {"from": "SPAWN", "to": "PLANNING"}}
{"op": "record-plan-approval", "at": "2026-03-01T10:01:30.000Z"}
{"op": "transition", "at": "2026-03-01T10:01:35.000Z", "detail": {"from": "PLANNING", "to": "RESPAWN"}}
{"op": "assign-iteration-task", "at": "2026-03-01T10:02:00.000Z", "detail": {"task": "implement auth module"}}
{"op": "transition", "at": "2026-03-01T10:02:05.000Z", "detail": {"from": "RESPAWN", "to": "DEVELOPING"}}In future iterations I’m thinking about moving to fully event-sourced and even persisting the events in a real DB for more advanced analysis as suggested by Yves Reynhout.
each state owns its completeness
As I was designing the workflow, I felt myself being pulled in a few directions. One of the interesting challenges was around transition validation. Should the existing state validate before transitioning, or should the new state validate that it’s pre-conditions are met.
I decided each state owns its completeness. For simplicity and maintainability, each state must prevent transitioning if it didn’t achieve the required actions of the state. And states should not have defensive checks for things that another state may have forgotten to do. If there is a problem we should fix the root cause and not work around with defensive checks that can cause their own problems.
code guides, agents follow
Don’t rely on agents to remember instructions. The agentInstructions field on each state definition points to a markdown file that gets injected into the agent on every state transition and whenever a workflow command fails. The agent’s context window is unreliable — the code re-teaches the agent what to do at every decision point.
 More fundamentally, this principle drives the whole concept. Leverage code, avoid reliance on fragile todo lists in markdown files.
More fundamentally, this principle drives the whole concept. Leverage code, avoid reliance on fragile todo lists in markdown files.
Testing
Something really exciting about this model evolution is testability. Thanks to the ddd principles of consolidating and decoupling the domain, it’s easier to test the workflow engine directly and simulate real Claude Code sessions.
All tests are black-box — they go through the public methods on Workflow and never test internal state definitions, the registry, or guards directly. This is done by creating an instance of Workflow with a specific state and calling methods on it:
describe('SPAWN state', () => {
it('transitions to PLANNING when issue set and developer and reviewer agents present', () => {
const state = stateWith({
githubIssue: 1,
activeAgents: ['developer-1', 'reviewer-1'],
})
const wf = Workflow.rehydrate(state, makeDeps())
const result = wf.transitionTo('PLANNING')
expect(result).toStrictEqual({ pass: true })
expect(wf.getState().state).toBe('PLANNING')
})
it('fails transition to PLANNING when no githubIssue', () => {
const state = stateWith({
activeAgents: ['developer-1', 'reviewer-1'],
})
const wf = Workflow.rehydrate(state, makeDeps())
const result = wf.transitionTo('PLANNING')
expect(result.pass).toBe(false)
})
it('fails transition to PLANNING when no developer agent', () => {
const state = stateWith({
githubIssue: 1,
activeAgents: ['reviewer-1'],
})
const wf = Workflow.rehydrate(state, makeDeps())
const result = wf.transitionTo('PLANNING')
expect(result.pass).toBe(false)
})
it('sets githubIssue and adds eventLog entry when recordIssue succeeds', () => {
const wf = Workflow.rehydrate({ ...INITIAL_STATE }, makeDeps())
const result = wf.recordIssue(42)
expect(result).toStrictEqual({ pass: true })
expect(wf.getState().githubIssue).toBe(42)
expect(wf.getState().eventLog).toStrictEqual(
expect.arrayContaining([expect.objectContaining({ op: 'record-issue', detail: { issueNumber: 42 } })])
)
})
it('fails recordIssue in non-SPAWN states', () => {
const state = stateWith({ state: 'PLANNING' })
const wf = Workflow.rehydrate(state, makeDeps())
const result = wf.recordIssue(42)
expect(result.pass).toBe(false)
})
})The tests construct a specific state, rehydrate a Workflow, call a public method, and assert the result. It provides the ability to simulate real AI agent behaviour in fast unit tests.
When you combine this with observability, it provides a slick continuous improvement feedback cycle. You observe Claude’s behaviour, when it does something wrong you check the internal state and event log, then you write a unit test against the workflow to recreate the state and validate the bug. Then you can fix it.
What’s the point of all this?
There is a part of me that enjoys the design challenge of refactoring the code to a more elegant solution. But that’s not why I’m doing this, although it certainly helps to motivate me.
The reason I am doing this is because I think that agent harnesses are becoming a key component of modern software engineering. AI follows instructions poorly. Writing things down in markdown files and hoping for the best is not a strategy that has worked for me.
Using real code to guide agents does work. But if the code is not well designed, it’s not easy to understand and fix problems when AI is not adhering to the desired workflow. A declarative, domain-driven approach solves that problem, enabling a smooth continuous improvement flow.
Next step: event-sourced Claude Code workflows.